# HStreamDB Overview
HStreamDB is a streaming database designed for streaming data, with complete lifecycle management for accessing, storing, processing, and distributing large-scale real-time data streams. It uses standard SQL (and its stream extensions) as the primary interface language, with real-time as the main feature, and aims to simplify the operation and management of data streams and the development of real-time applications.
# Why HStreamDB?
Nowadays, data is continuously being generated from various sources, e.g. sensor data from the IoT, user-clicking events on the Internet, etc.. We want to build low-latency applications that respond quickly to these incoming streaming data to provide a better user experience, real-time data insights and timely business decisions.
However, currently, it is not easy to build such stream processing applications. To construct a basic stream processing architecture, we always need to combine multiple independent components. For example, you would need at least a streaming data capture subsystem, a message/event storage component, a stream processing engine, and multiple derived data systems for different queries.
None of these should be so complicated, and this is where HStreamDB comes into play. Just as you can easily build a simple CRUD application based on a traditional database, with HStreamDB, you can easily build a basic streaming application without any other dependencies.
# Features
Note: The following features the milestone of HStreamDB version 1.0. Some features are under continuous development and not yet fully implemented in the current version. Please stay tuned.
# Streaming data processing via SQL
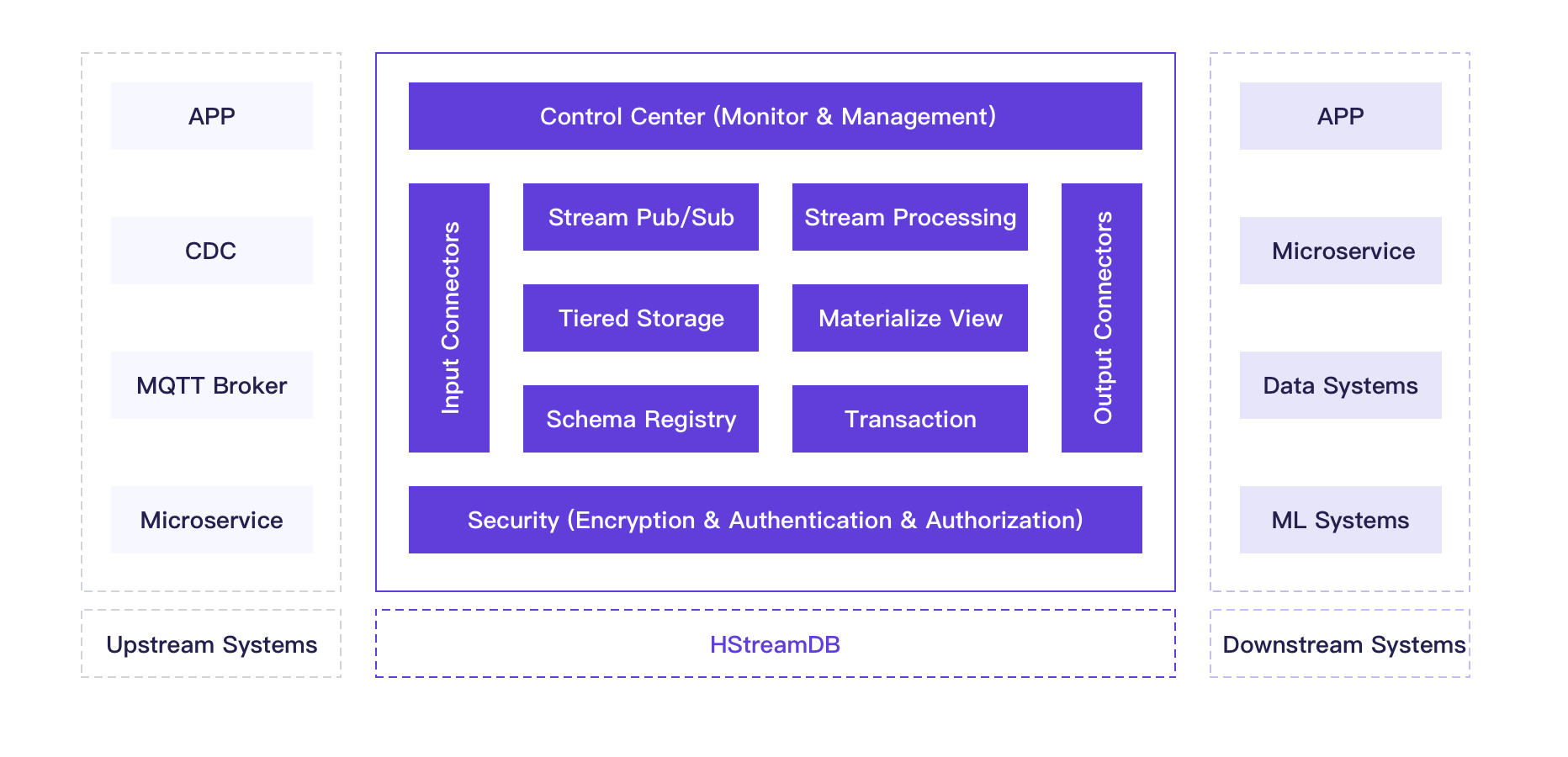
HStreamDB has designed a complete processing solution based on event time. It supports basic filtering and conversion operations, aggregations by key, calculations based on various time windows, joining between data streams, and processing disordered and late messages to ensure the accuracy of calculation results. Simultaneously, the stream processing solution of HStream is highly extensible, and users can extend the interface according to their own needs.
# Materialized View
HStreamDB will offer materialized view to support complex query and analysis operations on continuously updated data streams. The incremental computing engine updates the materialized view instantly according to the changes of data streams, and users can query the materialized view through SQL statements to get real-time data insights.
# Data Stream Management
HStreamDB supports the creation and management of large data streams. The creation of a data stream is a very lightweight operation based on an optimized storage design. It is possible to maintain a stable read/write latency in the case of many concurrent reads and writes.
# Persistent storage
HStreamDB provides low latency and reliable data stream storage. It ensures that written data messages are not lost and can be consumed repeatedly. HStreamDB replicates written data messages to multiple storage nodes for high availability and fault tolerance and supports dumping cold data to lower-cost storage services, such as object storage, distributed file storage, etc. This means the storage capacity can be infinitely scalable and achieve permanent storage of data.
# Data streams access and distribution
Connector deals with access and distribution of HStreamDB data. They connect to various data systems, including MQTT Broker, MySQL, ElasticSearch, Redis, etc., facilitating integration with external data systems for users.
# Monitoring and O&M tools
We will set up a web-based console with system dashboards and visual charts, enabling detailed monitoring of cluster machine status, system key indicators, etc., which make it more convenient for O&M staff to manage the cluster.