# HStreamDB 流数据库概述
HStreamDB 是一款专为流式数据设计的, 针对大规模实时数据流的接入、存储、处理、 分发等环节进行全生命周期管理的流数据库。它使用标准 SQL (及其流式拓展)作为主要 接口语言,以实时性作为主要特征,旨在简化数据流的运维管理以及实时应用的开发。
# 为什么选择 HStreamDB?
随着计算机和网络技术的迅猛发展以及向各行业的不断渗透,数据的产生方式和产生来源相 比以前都有了极大地丰富,比如:来自传感器的数据、网站上的用户活动数据、来自移动终 端和智能设备的数据、金融市场的实时交易数据,各种监控程序产生的数据等等。然而在如 今激烈竞争、复杂多变的商业环境下,营销时机转瞬即逝,风险防控必须分秒必争,商业决 策要求快速精准,因此数据的处理必须在更短的时间内得到结果,最好是能够做到实时处理 。
尽管如今越来越多的企业和组织已经认识到流处理的巨大价值并开始应用和部署相关的系统 ,但要落地一整套流处理技术栈却绝非易事。在实际实施的过程中就会发现当前的解决方案 普遍存在着:复杂难用、部署和运维麻烦、上手门槛高、组件杂乱、API 不统一、迁移困难 等问题。尤其当前基本的流处理方案都要涉及众多的分布式系统和组件,包括但不限于:实 时数据采集和捕获系统、实时数据存储系统、流计算引擎、下游的数据和应用系统。
事实上,一个专为流式数据设计的数据库系统,就可以解决以上的全部难题。HStreamDB 就 是这样的一款流数据库,就像你可以借助传统数据库轻松搭建一个简单的 CURD 应用一样, 借助 HStreamDB 你可以轻松无依赖地实现一个基本的流式的应用。
# HStreamDB 功能特性
注:以下功能特性为到 HStreamDB 1.0 版本为止的全部规划,部分功能正在持续开发中, 当前版本暂未实现,敬请期待。
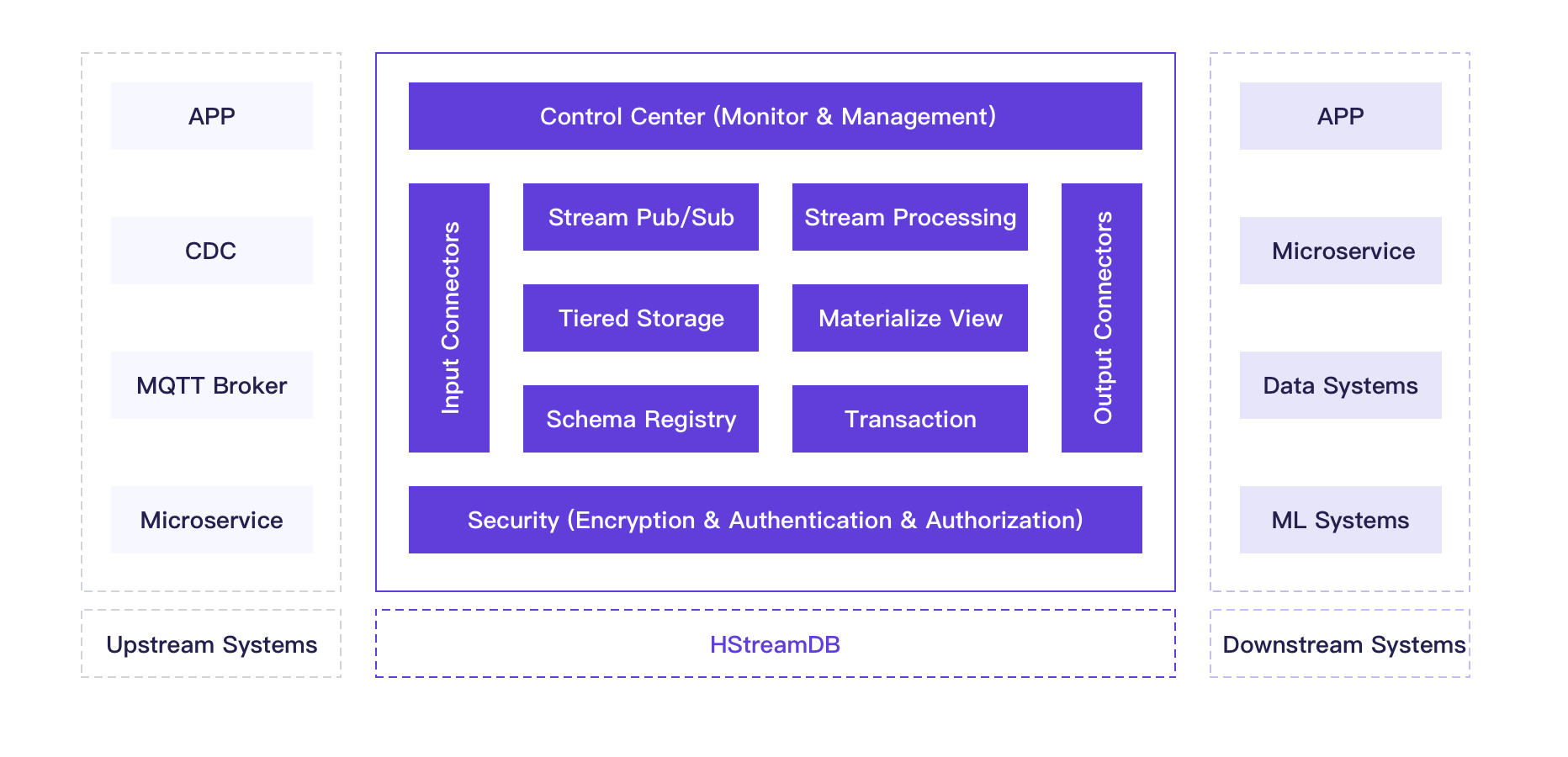
# 基于 SQL 的数据流处理
HStreamDB 设计了完整的基于事件时间的状态化处理方案,不仅支持基本的过滤、转换操作 ,还支持按 key 做聚合计算,基于多种时间窗口的计算,以及数据流之间 join 的能力, 同时也支持乱序和晚到的消息的特殊处理,保证计算结果的准确性。用户只需要通过 SQL 语句就能完成上述所有的处理功能,无需学习任何三方 API。同时,HStream 的流处理具备 丰富的扩展能力,用户可以针对自己的业务自行扩展。
# 数据流的物化查询
HStreamDB 提供物化视图功能,支持在持续更新的数据流上进行复杂的查询和分析操作。 HStreamDB 内部的增量计算引擎会根据数据流的变化实时更新物化视图,用户可通过 SQL 语句查询物化视图获得实时的数据洞察。
# 数据流管理
HStreamDB 支持创建和管理大量的数据流, 数据流的创建在 HStreamDB 是非常轻量的操作 , 同时基于优化的存储设计, 在大量数据流并发读写的情况下仍然能够保持稳定的读写延 迟。
# 数据流的持久化存储
HStreamDB 提供低延时的可靠的数据流存储,保证写入的数据消息不丢失,并且能够重复消 费。HStreamDB 会将写入的数据消息复制到多个存储节点,提供高可用和容错能力,同时支 持将冷数据转储到成本更低的存储服务上,比如对象存储、分布式文件存储等,存储的容量 可无限扩展,能够实现数据的永久存储。
# 数据流的接入和分发
HStreamDB 数据的接入和分发由 Connector 完成,它与包括 MQTT Broker、MySQL、ElasticSearch、Redis 等在内的多种数据系统相连接,方便用户和外部数 据系统进行集成。
# 监控和运维工具
HStreamDB 设置了基于 Web 的控制台,包含大量的系统仪表盘和可视化图表, 能够对集群 机器状态,系统关键指标等进行详细的监控,方便运维人员对集群进行管理。