HStreamDB v0.7 发布:透明分区、哈希算法,多项性能提升新尝试
新春伊始,我们非常高兴地向大家宣布:云原生分布式流数据库 HStreamDB 最新版本 v0.7 现已正式发布!
HStreamDB 是首个专为流数据设计的云原生流数据库,致力于为大规模数据流接入、存储、处理、分发等环节提供一站式管理,支持在动态变化的数据流上进行复杂的实时分析,并将在 IoT、互联网、金融等领域的实时流数据分析和处理场景发挥重要作用。
v0.7 的主要优化包括更高的稳定性、扩展性和可用性。在这一版本中,我们不仅通过集成测试、jepsen 测试等手段发现并修复了大量问题,提升了系统的稳定性,同时带来了若干新特性和改进,包括:透明分区功能、全新运维管理工具、新版 hstreamdb-java、集群负载均衡算法重构,以及使用和部署方面改进等。
最新版本下载地址:https://hub.docker.com/r/hstreamdb/hstream/tags
GitHub 项目地址:https://github.com/hstreamdb/hstream
新版本速览
新增透明分区功能,提升 Stream 的扩展能力
在之前的版本中 HStreamDB 已经能够支持存储和管理大规模的数据流(Stream),为了进一步提升单个 Stream 的扩展能力和读写性能,并保证数据的顺序性,HStreamDB v0.7 新增了透明分区功能:
- 从扩展性的角度来看,现在一个 stream 内部可能包含多个分区(分区的数量是动态变化的),读写流量将通过内部的分区在集群中实现负载均衡,从而实现单个 Stream 的更高吞吐。
- 从顺序性的角度来看,每条写入的数据会携带一个由用户指定的 orderingKey,每个 orderingKey 概念上对应一个逻辑分区,同一个逻辑分区内的数据将按照写入的顺序交付给同一个消费客户端,如下图所示。
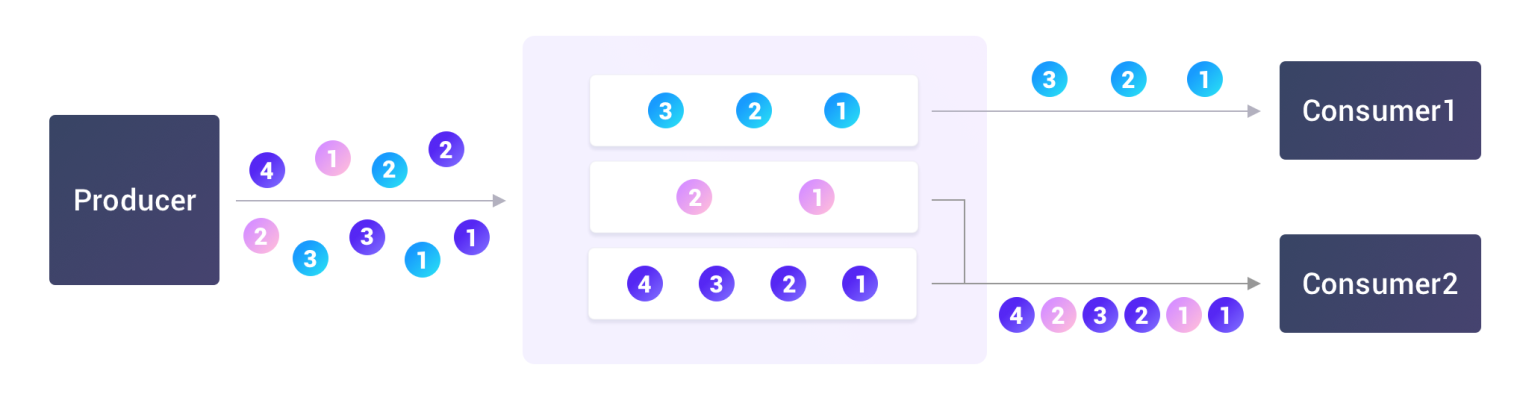
值得注意的是,在 HStreamDB v0.7 里分区对于用户来说是完全透明的,用户无需提前指定分区数量和分区逻辑,也不用担心分区的增加和减少带来的数据重分配以及数据乱序的问题。尽管从系统实现角度来看,分区是解决单点瓶颈、提升系统水平扩展能力的有效手段;但从使用者的角度来看,把分区直接暴露给用户,不仅破坏了上层的抽象,而且大大增加了用户的学习,使用以及维护成本。透明分区在实现扩展性、保证顺序性的同时,并没有将额外的复杂性暴露给用户,这将极大改善用户使用体验。
更详细的关于透明分区的介绍,请参考:HStreamDB Docs
改进集群负载均衡算法,提高分配效率
为了让集群内各节点的资源得到合理的利用,需要将客户端的读写流量尽可能均衡地分配到集群中的各节点上。HStreamDB v0.6 的负载均衡策略是基于节点的硬件资源负载情况来实现的,存在的主要问题是需要节点间相互通信交换多种硬件资源信息,包括 CPU、内存、网络等,同时这种方式存在一定的滞后性,总体来看实现相对复杂,效率较低。
为此在 HSteamDB v0.7 中我们基于一致性哈希算法重新实现新的负载均衡模块。一致性哈希是一个优雅而强大的算法,被多种分布式系统所采用,比如 DynamoDB。基于它的分配策略不仅使得负载均衡模块不用再实时维护硬件资源信息,而且核心算法更加简洁,也能很好应对集群成员变更的时候的重分配问题。同时它也很灵活,容易被扩展和优化,比如通过配置不同权重的方式应对异质节点。还有一些最新的研究优化,比如 Google 的 Consistent Hashing with Bounded Loads
新增 HStream Admin 工具,方便运维管理
我们提供了一个新的管理工具,以方便用户对 HStreamDB 的维护和管理。HAdmin 可以用于监控和管理 HStreamDB 的各种资源,包括 Stream、Subscription 和 Server 节点。以前嵌入在 HStream SQL Shell 中的 HStream Metrics,现也已迁移到了新的 HAdmin 中。简而言之,HAdmin 是为 HStreamDB 运维人员准备的,而 SQL Shell 是为 HStreamDB 终端用户准备的。
示例:
docker run -it --rm --name some-hstream-admin --network host hstreamdb/hstream:v0.7.0 bash
> hadmin --help
======= HStream Admin CLI =======
Usage: hadmin COMMAND
Available options:
-h,--help Show this help text
Available commands:
server Admin command
store Internal store admin command
> hadmin server status
+---------+---------+-------------------+
| node_id | state | address |
+---------+---------+-------------------+
| 100 | Running | 192.168.64.4:6570 |
| 101 | Running | 192.168.64.5:6572 |
+---------+---------+-------------------+
详细的使用方法请参考:HStreamDB Docs
hstreamdb-java v0.7 发布,支持 HStreamDB v0.7 新功能
hstreamdb-java 是当前主要的 HstreamDB 客户端,它将始终同步支持 HSteamDB 的最新特性。本次 HStreamDB v0.7 的新功能也在 hstreamdb-java v0.7 中得到了支持,具体的,相比 hstreamdb-java v0.6 ,除了若干问题的修复,hstreamdb-java v0.7 主要包含以下值得关注的新特性和改进:
- 新增了对 HStreamDB v0.7 透明分区功能的支持。
- 改进了对集群的支持,新增了请求在可恢复的失败情况下在集群中多个节点之间重试的能力。
- 新增
BufferedProducer接口和实现。考虑到不同场景下用户会对写入的时延和吞吐有不同的要求,为了清晰起见,我们将原来的Producer拆分成了两个独立的BufferedProducer和Producer,其中BufferedProducer主要面向高吞吐的场景,Producer主要用于低延迟的场景。 BufferedProducer新增两种flush模式。原来的Producer在 batch 模式下只支持按数据条数触发 flush,现在BufferedProducer新增了size-triggered 和 time-triggered 两种flush模式,同时这三类触发条件可以同时起作用,能够更灵活地满足用户的使用需求。
hstreamdb-java GitHub 仓库:https://github.com/hstreamdb/hstreamdb-java
简化部署与使用的流程,提升使用体验
- 为了方便用户快速体验以及使用 HStreamDB,我们现已增加基于 docker-compose 的快速上手文档:https://hstream.io/docs/en/latest/start/quickstart-with-docker.html
- 为了支持用户在多台机器上快速部署和使用 HStreamDB 集群,我们开发了专门的集群部署脚本,可通过以下链接下载 https://github.com/hstreamdb/hstream/blob/main/script/dev-deploy
- 随着 HStreamDB 配置项的不断增加,原有的通过命令行选项传递配置的方式不太足够,因此我们又引入了通过配置文件的方式来统一管理配置项,请参考:https://hstream.io/docs/en/latest/reference/config.html#configuration-table
未来规划
在接下来的开发工作中,我们将重点实现以下目标:
- 持续提升系统的稳定性,达到生产可用
- 持续改善系统可用性和运维监控能力,增强安全性支持
- 对现有的流处理引擎进行升级,带来更强大的实时处理和分析能力
敬请期待!